
@TOC
Eureka note
github
https://github.com/Netflix/eureka
注:这个note是自”https://github.com/Netflix/eureka/wiki“整理翻译过来的。(2020-03-02)
简介
Eureka是一个基于REST (Representational State Transfer)的服务,主要用于AWS云中的服务定位,
以实现中间层服务器的负载平衡和故障转移。
Building
由于一些必需的库是java8(servo),所以构建需要java8,但是源和目标兼容性仍然设置为1.7。
注意,应该签出tag标记来执行构建。
Eureka 1.0
- 粗看Eureka
- 配置Eureka
- 构建Eureka客户端与服务端
- 运行Demo应用
- 在EC2中发布Eureka服务端
- 理解Eureka 客户端/服务端 通信
- 服务端自保模式
- Eureka REST 操作
- 理解Eureka点对点通信
- 覆写默认配置项
- FAQ(aka:frequently asked questions;常见问题)
Eureka 2.0(已停止)
Eureka 2.0上现有的开源工作已经停止。在现有的工作仓库的2.x分支上发行的代码库和工件部分,使用时需要自担风险。
Eureka1.x是Netflix服务发现系统的核心部分,现在仍然是一个活跃的项目。
Eureka 1.0 WIKI
Eureka at a glance
Eureka是什么?
Eureka是一个基于REST (Representational State Transfer)的服务,主要用于AWS云中的服务定位,以实现中间层服务器的负载平衡和故障转移。
我们称这个服务为Eureka服务端。
Eureka还附带了一个基于java的客户端组件,即Eureka客户端,它使与服务的交互变得更加容易。
客户端还有一个内置的负载均衡器,它执行基本的轮循负载平衡。
在Netflix,一个更复杂的负载均衡器封装了Eureka,以提供基于流量、资源使用、错误条件等几个因素的加权负载平衡,以提供卓越的弹性。
Eureka有什么作用?
在AWS云中,由于其固有的特性,服务器来来往往。与传统的负载均衡器不同,传统的负载均衡器使用的是已知IP地址和主机名的服务器,
而在AWS中,负载均衡需要更复杂的技术来动态注册和注销服务器。
由于AWS还没有提供中间层负载平衡器,Eureka填补了中间层负载平衡领域的一个巨大空白。
Eureka和AWS ELB 有什么不同?
AWS弹性负载平衡器是面向终端用户web流量的边缘服务的负载平衡解决方案。Eureka满足了中间层负载平衡的需求。
虽然理论上你可以把中间层服务放在AWS ELB后面,但在EC2 classic中,你把中间层服务暴露给外界,这样就失去了AWS安全组的所有用处。
Eureka和Route 53 有什么不同?
Route 53是一种命名服务,类似于Eureka可以为中间层服务器提供相同的服务,但相似之处仅限于此。
Route 53是一个DNS服务,它可以托管你的DNS记录,即使是非aws数据中心。Route 53也可以跨AWS区域进行基于延迟的路由。
Eureka类似于内部DNS,与世界各地的DNS服务器没有任何关系。
Eureka也是区域隔离的,也就是说它不知道AWS其他区域的服务器。它保存信息的主要目的是为了在区域内实现负载平衡。
Eureka在Netflix是如何使用的?
在Netflix,除了在中间层负载平衡中扮演关键角色外,Eureka还用于以下目的。
- 通过Netflix Asgard进行红黑部署 - 一个使云部署更容易的开源服务。Eureka通过与Asgard交互, 在出现问题时快速无缝地部署服务的新旧版本。
- 使我们部署的cassandra在需要维护时得以在流量中抽取出实例。
- 使我们的memcached缓存服务得以识别环中的节点列表。
- 用于由于各种其他原因而携带关于服务的其他应用程序特定元数据。
什么时候该使用Eureka?
你通常在AWS云中运行,并且你有大量的中间层服务,你不希望这些服务注册到AWS ELB或暴露来自外部世界的流量。
您要么正在寻找一个简单的轮询负载平衡解决方案,要么愿意根据您的负载平衡需求编写您自己的Eureka包装器。
您不需要保持会话,而是在外部缓存(如memcached)中加载会话数据。
更重要的是,如果您的架构适合使用基于客户端的负载平衡器的模型,那么Eureka就可以很好地适应这种用法。
应用程序客户端和应用程序服务端让如何通信?
通讯技术可以是你喜欢的任何东西。
Eureka帮助您找到有关您想要通信的服务的信息,但不会对通信协议或方法施加任何限制。
例如,您可以使用Eureka来获取目标服务器地址,并使用诸如thrift、http(s)或任何其他RPC机制之类的协议。
高层体系结构
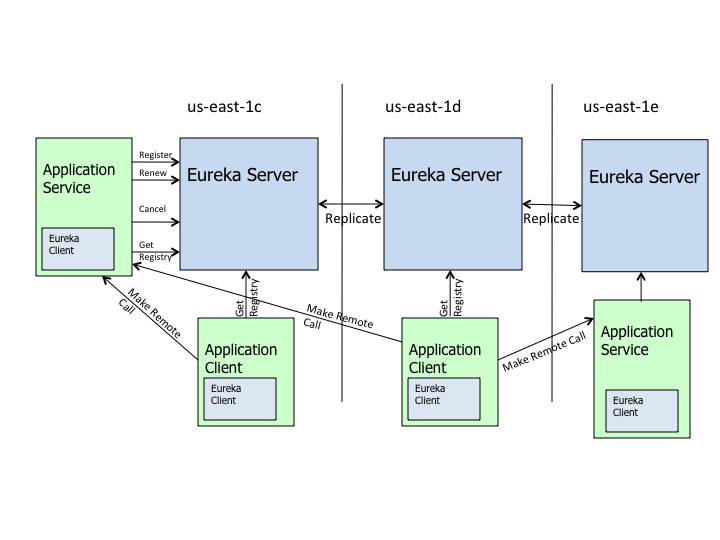
上面的架构描述了Eureka是如何在Netflix上部署的,这是你通常运行它的方式。
每个区域有一个eureka集群,它只知道其区域内的实例。每个区域至少有一个Eureka服务端来处理区域故障。
服务向Eureka注册,然后每30秒发送心跳信号更新租约。如果客户端不能续订租约几次,它将在大约90秒内从服务器注册表中删除。
注册信息和续订复制到集群中的所有eureka节点。
来自任何区域的客户端可以查找注册表信息(每30秒发生一次),以定位它们的服务(可以在任何区域)并进行远程调用。
非java服务和客户端
对于非基于Java的服务,您可以选择用服务的语言实现eureka的客户端部分,或者运行“side car”,
它本质上是一个Java应用程序,其中嵌入了一个处理注册和心跳的eureka客户端。
对于Eureka客户端支持的所有操作,也公开了基于REST的端点。
非java客户端可以使用REST端点来查询有关其他服务的信息。
可配置能力
使用Eureka,您可以动态地添加或删除集群节点。您可以从超时调优内部配置到线程池。
Eureka使用archaius,如果您有一个配置源实现,那么许多这些配置都可以动态调优。
弹性能力
在AWS云环境中,我们很难不考虑我们构建的所有东西的弹性。Eureka从我们获得的经验中受益,客户端和服务器都内置了弹性。
构建Eureka客户端是为了处理一个或多个Eureka服务端的故障。由于Eureka客户端中包含注册表缓存信息,因此即使在所有Eureka服务器都宕机的情况下,它们也可以很好地运行。
Eureka服务端对其他Eureka服务器的下降具有弹性。即使在客户端和服务器之间的网络分区期间,服务器也具有内置的弹性,可以防止大规模停机。
监控能力
Eureka使用servo来跟踪客户端和服务器中的大量信息,以获得性能、监视和警报。数据通常在JMX注册表中可用,可以导出到Amazon Cloud Watch。
Configuring Eureka
阅读Eureka-at-a-glance 页面以更好地理解设置的概念。
Eureka包含两个组件——Eureka客户端和Eureka服务端。使用Eureka的体系结构通常有两个应用程序
- 应用程序客户端 使用Eureka客户端向应用程序服务端发出请求。
- 应用程序服务端 接收来自应用程序客户端的请求并发回响应。
设置包括以下
- Eureka服务端
- 应用程序客户端的Eureka客户端
- 应用程序服务端的Eureka客户端
Eureka可以在AWS和非AWS环境中运行。
如果在云环境中运行,则需要传入java命令行参数-Deureka.datacenter=cloud以便于Eureka客户端/服务端知道初始化特定于AWS云的信息。
配置Eureka客户端
先决条件
- JDK 1.8或更高版本
您可以通过以下选项获得Eureka客户端二进制文件。总是尝试获得最新的版本,因为往往会有更多的修复。
- 您可以使用这个URL下载Eureka客户端二进制文件”http://search.maven.org/#search%7Cga%7C1%7Ceureka-client“
- 您可以将Eureka客户端作为maven依赖项添加
1
2
3
4
5<dependency>
<groupId>com.netflix.eureka</groupId>
<artifactId>eureka-client</artifactId>
<version>1.1.16</version>
</dependency> - 您可以按照这里这里指定的方式构建客户端。
配置
配置Eureka客户端最简单的方法是使用properties属性文件。默认情况下,Eureka客户端搜索类路径中的属性文件eureka-client.properties。
Eureka客户端会进一步搜索环境特定的属性文件中声明的属性进行覆盖。
环境通常是test或prod,由*-Deureka.environment*的java命令行参数提供,切换到eureka客户端(不带.properties后缀)。
相应地,客户端也会搜索eureka-client-{test,prod}.properties。
您可以在这里查看默认配置的示例。
您可以复制这些配置并根据需要进行编辑,并将它们放置在类路径中。
如果出于某种原因想要更改属性文件的名称,可以在java命令行开关中指定-Deureka.client.props=(不带后缀),其中是要搜索的属性文件的名称。
文件中的属性解释了它们的用途。至少需要配置以下内容:
1 | Application Name (eureka.name) |
有关更高级的配置,请查看以下链接中的可用选项。
https://github.com/Netflix/eureka/blob/master/eureka-client/src/main/java/com/netflix/appinfo/EurekaInstanceConfig.java
https://github.com/Netflix/eureka/blob/master/eureka-client/src/main/java/com/netflix/discovery/EurekaClientConfig.java
配置Eureka服务端
先决条件
- JDK版本为1.8及以上
- Tomcat版本为6.0.10及以上
使用Eureka服务端,您可以通过以下方式获取二进制文件
- 您可以从这里这里指定的源构建WAR archive存档。
- 您可以使用这个URL从mavencentral下载WAR存档”http://search.maven.org/#search%7Cga%7C1%7Ceureka-server“
配置
Eureka服务端有两组配置
- Eureka客户端配置如上所述。
- Eureka服务端配置。
配置Eureka服务端最简单的方法是使用类似于上面的Eureka客户端的属性文件。首先,按照上面指定的方式配置与服务器一起运行的Eureka客户端。
Eureka服务端本身启动一个Eureka客户端,它使用这个客户端来寻找其他Eureka服务端。
因此,您需要首先为Eureka服务端配置Eureka客户端,就像您对连接到Eureka服务的任何其他客户端所做的那样。
Eureka服务端将使用其Eureka客户端配置来识别具有相同名称(即eureka.name)的对等Eureka服务端
在配置了Eureka客户端之后,如果您正在AWS中运行,您可能需要配置Eureka服务端。
Eureka服务端默认搜索类路径中的属性文件eureka-server.properties。
它会进一步在特定于环境的属性文件中搜索特定的环境覆盖。
环境通常是test或prod,由java命令行*-Deureka.environment*提供的切换Eureka服务端(不带.properties后缀)。
相应地,服务端也会搜索eureka-server-{test,prod}.properties。
为本地开发进行配置
当运行Eureka服务端进行本地开发时,通常需要等待约3分钟,直到它完全启动。
这是由于默认的服务器行为,搜索对等点同步,并在没有找到可用的对等点时重试。
可以通过设置属性eureka.numberRegistrySyncRetries=0来减少此等待时间。
AWS的配置
如果您像这里解释的那样在AWS中运行,则需要额外的配置。
有关更高级的服务器配置,请参考这里提供的选项。
如果你在构建WAR archive存档, 你可以编辑eureka-server/conf下对应的配置文件,在创建archive存档之前,构建将负责放置这些属性文件到WEB-INF/classes目录下
如果您从maven下载archive存档,那么您可以自己将编辑过的属性文件合并到WEB-INF/classes下。
运行演示应用程序可以帮助您更好地理解配置。
客户端/服务端版本的兼容性
我们使用Semantic Versioning(什么是Semantic Versioning?)来管理Eureka。
并将在小版本升级内维护客户端/服务端协议兼容性(例如1。x版本应该在客户端和服务端部署之间有兼容的协议)。
一般来说,让服务端使用比客户端更新的版本总是更安全的。
Building Eureka Client and Server
前置条件
- Git版本1.7.11.3或更高
构建步骤
- 安装最新的git包。
- 从github获得Eureka来源
git clone https://github.com/Netflix/eureka.git - 现在,通过在提取源代码的目录中执行以下操作来构建Eureka服务端。
1
2cd eureka
./gradlew clean build - 您可以找到以下的artifacts工件
- Eureka Server WAR archive (./eureka-server/build/libs/eureka-server-XXX.war )
- Eureka Client (./eureka-client/build/libs/eureka-client-XXX.jar )
- Dependencies (./eureka-server/testlibs/) (如果您不想使用maven来下载依赖项,可以使用这些archives存档)
Running the Demo Application
演示应用程序打包附带了配置、构建和运行运行Eureka所需的所有组件的能力
- Eureka Server
- Application Service
- Application Client
有关了解配置的更多细节,请访问此页面。
关于Demo
Demo将帮助您设置一个Eureka服务端,监听您选择的端口。
它还将帮助您设置将提供请求的应用程序服务和将向该服务发送请求的应用程序客户端。
应用程序服务注册到Eureka服务端,应用程序客户端可以查找并将请求发送到应用程序服务。
客户端和服务端在交易消息之后优雅地退出。
关于Demo服务端的声明
Demo演示服务端被配置为易于为演示用例进行设置,但没有配置为适合于生产使用。仅限于了解如何正确配置Eureka服务端。
Eureka服务端配置
- 切换到eureka-server/conf/目录下,并按需修改编辑eureka-client.properties和eureka-client-test.properties文件。(你不需要编辑eureka-server.properties属性文件,除非您正在设置服务端的高级配置)
- 构建应用程序
- 上面的构建还设置了运行演示服务和演示客户端所需的所有库。
- 拷贝WAR artifact到你tomcat 部署目录的
——¥TOMCAT_HOME/webapps/下1
cp ./eureka-server/build/libs/eureka-server-XXX-SNAPSHOT.war $TOMCAT_HOME/webapps/eureka.war
- 启动tomcat服务器。访问http://localhost:8080/eureka以验证那里的信息。您的服务器的eureka客户端应该在30秒内注册,您应该在那里看到这些信息。
应用程序服务的Eureka客户端配置
- 导航到eureka-examples/conf目录并按需修改编辑sample-eureka-service.properties文件
应用程序客户端的Eureka客户端配置
- 导航到eureka-examples/conf目录并按需修改编辑sample-eureka-client.properties文件
运行Demo
参见示例说明https://github.com/Netflix/eureka/tree/master/eureka-examples
Deploying-Eureka-Servers-in-EC2
端点配置概述
Eureka服务端需要进行配置,以便每个服务端都知道其他所有对等服务端。请参阅下面的示例,了解如何为DNS方法和基于属性的方法做到这一点。
此外,eureka服务端复制可以批处理,以提高效率。若要启用批量复制,请设置eureka.shouldBatchReplication=true。有关更多细节,请参阅DefaultEurekaServerConfig.java。
AWS配置概述
在AWS云中,实例来来往往。这意味着您无法使用标准主机名或IP地址来识别Eureka服务端。
但是,由于Eureka服务端可以帮助您识别更改主机名的其他服务,因此您需要Eureka服务器的一组标准的、可很好识别的地址。
这就是AWS EC2弹性IP地址派上用场的地方。如果您以前没有听说过弹性IP地址,那么这是一份必读。
第一步是为您将使用安装程序运行的Eureka服务端获取一个弹性IP。
理想情况下,您应该使用这里指定的架构运行Eureka。 因此,集群中的每台服务器都需要一个弹性IP。
一旦您使用弹性ip地址列表配置了您的Eureka服务端,Eureka服务器将处理查找未使用的弹性ip并在启动期间将其绑定到自身的麻烦。
通常在AWS区域内的Eureka集群有一个ASG,实例启动被配置为平均分布到所有区域。
这意味着,对于冗余和区域故障,每个区域至少要启动一个Eureka服务端。每当一个实例被杀死时,ASG就会在清空的区域内启动一个新的Eureka服务器。
新服务器将从该区域选择一个自由的弹性IP,并将自己绑定到那里。
对于正在访问Eureka服务端的客户端来说,这是透明的,而且业务正常,因为Eureka客户端会自动故障转移到其他服务器,然后在服务器恢复时再次重新连接。
弹性IPs有两种配置方式,根据用户需要的灵活程度不同。
在Netflix,我们希望透明地添加新的区域或新的Eureka服务端,因此我们使用DNS模型来分配新的eip,客户端和服务器都可以动态地找到它们。
将一个简单的模型来定义他们的尤里卡配置文件,但缺点是,
他们限于AMI和比如分布式下的1000个的实例需要互相交谈和添加或删除区域可能非常棘手,
因为你需要部署新的AMI与改变所有客户端的配置。
使用property属性文件配置EIPs
在Eureka服务端中配置的第一个信息是区域的可用区域。
这在eureka-client.properties(或eureka-client-test.properties 或eureka-client-prod.properties,如果你想要环境覆盖)中完成。
以下面为例,”us-east-1”区域设置3个可用分区us-east-1c、us-east-1d、us-east-1e。
1 | eureka.us-east-1.availabilityZones=us-east-1c,us-east-1d,us-east-1e |
接下来,您要为Eureka侦听请求的每个区域配置服务url。通过提供以逗号分隔的列表,可以为一个区域配置多个Eureka服务端。
1 | eureka.serviceUrl.us-east-1c=http://ec2-552-627-568-165.compute-1.amazonaws.com:7001/eureka/v2/,http://ec2-368-101-182-134.compute-1.amazonaws.com:7001/eureka/v2/ |
然后,相同的配置将包含在注册到Eureka服务的Eureka客户端和希望从Eureka服务端找到服务的Eureka客户端中。
通过DNS方式配置EIPs
如果您正在寻找灵活性,您应该使用DNS配置Eureka服务url。
首先为区域配置一个DNS名称,该名称可用于查找可用区域列表。 因为使用DNS,您只能为DNS名称找到一个CNAME,所以我们使用TXT记录来查找DNS名称列表。
例如,下面是DNS服务器中创建的DNS TXT记录,它列出了一个区域可用的DNS名称集。
1 | txt.us-east-1.mydomaintest.netflix.net="us-east-1c.mydomaintest.netflix.net" |
然后,可以为每个区域递归地定义TXT记录,如下所示(如果每个区域有多个主机名,则使用空格分隔)
1 | txt.us-east-1c.mydomaintest.netflix.net="ec2-552-627-568-165.compute-1.amazonaws.com" |
然后在Eureka服务端(Eureka -client.properties)和所有Eureka客户端中指定以下属性,以便它们能够查找DNS并找到通信所需的信息。
1 | eureka.shouldUseDns=true |
在Netflix,我们使用这个模型来动态 增加/删除 新的Eureka服务端,从而在几分钟内将信息传播到数千个客户端。
使用服务urls分配EIPs
那么,当我们要为服务器分配EIPs时,为什么还要定义URLs呢?任何两个希望彼此通信的实例通常使用公共主机名,以便AWS安全组遵守安全性限制。
Eureka服务端使用这些URL彼此通信,每个URL包含一个公共主机名(ec2-552-627-568-170.compute-1.amazonaws.com),它来自一个弹性IP(552.627.568.170)。
Eureka服务端根据它所启动的区域找到一个EIP。然后,它尝试从该区域找到一个未使用的EIP,然后在启动期间将该EIP绑定到自己。
Eureka如何找到未使用的EIPs? 它使用Eureka客户端来查找对等实例列表,查看它们与哪些EIPs绑定,并选择未绑定的eip。
它倾向于找到分配给它所在区域的EIP,这样该区域中所有其他实例的Eureka客户端就可以与位于同一区域的Eureka服务端进行通信。
如果Eureka服务端不能在其区域找到任何空闲的eip,它将尝试在其他区域中分配的eip。
如果所有这些都被绑定,那么Eureka服务端就会启动并等待一个EIP变成空闲的,并每5分钟尝试一次绑定EIP。
Eureka客户端同样尝试寻找位于同一区域的Eureka服务端,如果它们找不到任何服务器,它们将故障转移到其他区域的Eureka服务器。
Eureka故障转移
当为客户端提供了Eureka服务端列表时,Eureka客户端将自动故障转移到集群中的其他节点。让我们考虑下面的配置来理解它是如何工作的
1 | eureka.us-east-1.availabilityZones=us-east-1c,us-east-1d,us-east-1e |
我们定义了3个区域(us-east-1c, us-east-1d和us-east- 1e),每个区域只有一个EIP。
比方说,例如Eureka服务端运行在us-east-1c位置http://ec2-552-627-568-165.compute-1.amazonaws.com:7001/eureka/v2/fails,
所有eureka客户自动到下一个服务器通信区位于http://ec2-552-627-568-170.compute-1.amazonaws.com:7001/eureka/v2/。
如果失败,客户端将尝试列表中的下一个,以此类推。
当失败的服务器重新启动时,eureka客户端自动重新连接到其区域中的服务器。
Eureka的AWS特殊properties属性配置
在AWS云环境中,传入java命令行属性 -Deureka.datacenter=cloud 这样Eureka客户端/服务器就知道初始化特定于AWS云的信息。
Eureka服务端需要AWS访问才能在EC2中运行。对此有两种选择。
使用默认配置(no),服务器将使用EC2实例上的InstanceProfileCredentials,或者您也可以通过配置显式设置AWS accessId和secretKey:
1 | eureka.awsAccessId= |
AWS访问策略
Eureka尝试查询ASG相关信息,以确保启动的实例自动OUT_OF_SERVICE退出服务或启动,这取决于Autoscaling group属性中的“addToLoadbalancer”标志的值。
在配置Eureka客户端时,通过指定此属性来配置用于确定您属于哪个ASG的属性。
1 | eureka.asgName |
通过Eureka服务端可以查询ASG信息,也可以对云中的IPs进行绑定/解绑定。因此AWS策略应该配置为允许上述访问。下面是一个带有所需访问的示例策略。
1 | { |
Understanding Eureka Client-Server Communication
希望现在您已经访问了这个页面,了解了如何设置Eureka服务端。
与Eureka服务端交互的第一步是初始化Eureka客户端。如果您正在AWS云中运行,您可以按以下方式初始化:
从1.1.153版开始,引入了EurekaModule类,允许将eureka-client与governator/guice一起使用。请看这个governated example受治理的例子。
预发布版本为1.1.153,您可以通过以下方式初始化Eureka客户端
1 | DiscoveryManager.getInstance().initComponent( |
如果在其他数据中心运行,则按照以下方式进行初始化
1 | DiscoveryManager.getInstance().initComponent( |
Eureka客户端则会寻找eureka-client.properties文件,像这里描述的。
关于实例的状态
默认情况下,Eureka客户端在启动状态下启动,这给了实例一个机会在它可以服务流量之前进行特定于应用程序的初始化。
然后,应用程序可以通过将实例状态变为UP来显式地放置流量的实例。
1 | ApplicationInfoManager.getInstance().setInstanceStatus(InstanceStatus.UP) |
应用程序还可以注册健康检查回调,这可以选择性地将实例状态更改为DOWN。
1 | ApplicationInfoManager.getInstance().setInstanceStatus(InstanceStatus.UP) |
应用程序还可以注册健康检查回调,这可以选择性地将实例状态更改为DOWN。
在Netflix,我们也使用OUT_OF_SERVICE退出服务状态,主要是为了从流量中提取一个实例。它用于在出现问题时方便地回滚新修订的部署。
大多数应用程序会为新的版本创建新的ASG,流量会被路由到新的ASG。
在出现问题的情况下,回滚修订只是通过将ASG中的所有实例设置为OUT_OF_SERVICE来关闭流量的问题。
Eureka客户端操作
Eureka客户端首先尝试与 AWS 云中同一区域的尤里卡服务器进行所有操作,如果找不到服务器,就会切换到其他区域。
应用程序客户端可以通过使用 Eureka 客户机返回的信息来实现负载平衡。
下面是示例应用程序的示例,它使用 Eureka 客户端返回的信息来平衡客户机的负载。
1 | InstanceInfo nextServerInfo = DiscoveryManager.getInstance() |
如果基本的循环负载平衡不足以满足您的需求,那么您可以在这里提供的 API/操作之上包装一个负载平衡器。
在 AWS 云中,请确保重试失败,并将超时时间保持在较低水平,因为可能会出现这样的情况: Eureka服务端可能返回在中断情况下不再存在的实例。
需要注意的是,Eureka 客户端清理为服务器通信而创建的空闲超过30秒的 HTTP 连接。
这是因为 AWS 防火墙限制不允许通信在空闲几分钟后通过连接。
Eureka 客户端通过以下方式与服务器交互。
注册
Eureka 客户端向 Eureka 服务器注册有关运行实例的信息。
在 AWS 云中,关于实例的信息可以通过访问 URL/ http://169.254.169.254/latest/metadata 来获得。
注册发生在第一次心跳时(30秒后)。
更新
Eureka客户需要通过每30秒发送一次心跳来延长租约。更新通知 Eureka 服务器实例仍然活着。
如果服务器90秒内没有看到更新,那么它会将实例从注册表中删除。
建议不要更改更新间隔,因为服务器使用这些信息来确定客户端到服务器的通信是否存在广泛的问题。
获取注册表
Eureka 客户端从服务器获取注册表信息并在本地缓存它。之后,客户端使用这些信息来寻找其他服务。
通过获取最后一次提取周期和当前一次提取周期之间的增量更新,定期(每30秒)更新此信息。
增量信息在服务器中保存的时间更长(大约3分钟) ,因此增量取出可能会再次返回相同的实例。
Eureka 客户端自动处理重复的信息。
获得 deltas 之后,Eureka 客户端通过比较服务器返回的实例计数,将信息与服务器进行协调, 如果由于某种原因信息不匹配,则再次获取整个注册表信息。
Eureka服务端缓存 deltas 的压缩有效负载、整个注册表以及每个应用程序的压缩有效负载以及相同的未压缩信息。
有效负载还支持 JSON/XML 格式。Eureka 客户端使用 jersey apache 客户机获取压缩 JSON 格式的信息。
取消
Eureka客户端在关闭时向尤里卡服务器发送一个取消请求。这将从服务器的实例注册表中删除实例,从而有效地将实例从流量中删除。
这是在 Eureka 客户端关闭时完成的,应用程序应该确保在关闭期间调用以下命令。
1 | DiscoveryManager.getInstance().shutdownComponent() |
时间延迟
所有来自 Eureka 客户端的操作可能需要一些时间来反映在 Eureka 服务器中,并随后反映在其他 Eureka 客户端中。
这是因为有效负载缓存在 eureka 服务器上,该服务器会定期刷新以反映新的信息。 Eureka的客户端也会定期获取 deltas。
因此,将更改传播到所有 Eureka 客户端可能需要2分钟。
沟通机制
默认情况下,Eureka 客户端使用 Jersey 和 Jackson 以及 JSON 有效负载与 Eureka 服务器进行通信。
您总是可以通过覆盖默认机制来使用自己选择的机制。
注意,XStream也是一些遗留用例的依赖关系图的一部分。
Server Self Preservation Mode
自我保护模式
如果Eureka服务端发现有大量注册用户以一种不体面的方式终止了他们的连接,并且同时等待被驱逐,那么他们将进入自我保护模式。
这样做是为了确保灾难性网络事件不会擦除 eureka 注册数据,并将其传播到所有客户端。
为了更好地理解自我保护,它首先帮助我们理解尤里卡客户如何结束他们的注册生命周期。
尤里卡协议要求客户执行一个明确的取消注册行动时,他们是永久离开。
例如,在提供的 java 客户端中,这是在 shutdown()方法中完成的。任何连续3次心跳续订失败的客户,
将被视为不干净的终止,并将通过背景驱逐程序被驱逐出去。
只有当大于15% 的当前注册表处于这种后期状态时,自我保护才会启动。
当处于自我保护模式时,Eureka服务端将停止驱逐所有实例,直到:
- 它看到的心跳续订次数已经回到预期阈值之上,或者
- 自我保护功能丧失(见下文)
自我保存是默认启用的,启用自我保存的默认阈值大于当前注册表大小的15% 。
如何配置自我保护阈值
这里定义了自我保护配置,要更改示例中的自我保护阈值,请设置以下属性: eureka.renewwalpercentthreshold=[0.0,1.0]。
如何禁用自我保护
这里定义了自我保护配置,要在示例中禁用自我保护,请设置以下属性: eureka.enableSelfPreservation=false。
在生产环境中,如果由于某种原因,你的服务器进入了自我保护模式,你可以通过暂时禁用配置自我保护来迫使服务器脱离自我保护模式。
我们希望在这种情况下,人工操作能够评估情况并采取适当的行动。
Eureka REST operations
以下是非 java 应用程序可以使用 Eureka 的 REST 操作。
appID 是应用程序的名称,instanceID 是与实例关联的唯一 id。
在 AWS 云中,instanceID 是实例的实例 id,在其他数据中心中,它是实例的主机名。
对于 JSON/XML,提供的内容类型必须是 application/XML 或 application/JSON。
| 操作 | http动作 | 描述 |
|---|---|---|
| Register new application instance | POST /eureka/v2/apps/appID | Input: JSON/XML payload HTTP Code: 204 on success |
| De-register application instance | DELETE /eureka/v2/apps/appID/instanceID | HTTP Code: 200 on success |
| Send application instance heartbeat | PUT /eureka/v2/apps/appID/instanceID | HTTP Code: 200 on success 404 if instanceID doesn’t exist |
| Query for all instances | GET /eureka/v2/apps | HTTP Code: 200 on success Output: JSON/XML |
| Query for all appID instances | GET /eureka/v2/apps/appID | HTTP Code: 200 on success Output: JSON/XML |
| Query for a specific appID/instanceID | GET /eureka/v2/apps/appID/instanceID | HTTP Code: 200 on success Output: JSON/XML |
| Query for a specific instanceID | GET /eureka/v2/instances/instanceID | HTTP Code: 200 on success Output: JSON/XML |
| Take instance out of service | PUT /eureka/v2/apps/appID/instanceID/status?value=OUT_OF_SERVICE | HTTP Code: 200 on success 500 on failure |
| Move instance back into service (remove override) | DELETE /eureka/v2/apps/appID/instanceID/status?value=UP | HTTP Code: 200 on success 500 on failure |
| Update metadata | PUT /eureka/v2/apps/appID/instanceID/metadata?key=value | HTTP Code: 200 on success 500 on failure |
| Query for all instances under a particular vip address | GET /eureka/v2/vips/vipAddress | HTTP Code: 200 on success Output: JSON/XML 404 if the vipAddress does not exist. |
| Query for all instances under a particular secure vip address | GET /eureka/v2/svips/svipAddress | HTTP Code: 200 on success Output: JSON/XML 404 if the svipAddress does not exist. |
注册
注册时,需要发布一个符合这个XSD的XML(或JSON)主体
1 |
|
更新
1 | Example : PUT /eureka/v2/apps/MYAPP/i-6589ef6 |
取消
(如果Eureka在evictiondurationsens事件内没有从服务节点获得心跳,那么该节点将自动注销)
1 | Example : DELETE /eureka/v2/apps/MYAPP/i-6589ef6 |
Understanding Eureka Peer to Peer communication
确保您访问过此页面以了解Eureka集群的配置。
Eureka客户端尝试与同一区域的Eureka服务端通话。如果与服务器通信时出现问题,或者服务器不在同一区域中,则客户端将故障转移到其他区域中的服务器。
一旦服务器开始接收流量,在服务器上执行的所有操作都将复制到服务器知道的所有对等节点。
如果某个操作由于某种原因而失败,则在下一个心跳信息上调节该信息,该心跳信息也将在服务器之间复制。
当 Eureka 服务器出现时,它尝试从邻近节点获取所有实例注册表信息。 如果从一个节点获取信息有问题,服务器在放弃之前尝试所有对等节点。
如果服务器能够成功地获得所有实例,它将基于该信息设置应该接收的更新阈值。
如果任何时候,更新低于为该值配置的百分比(15分钟内低于85%) ,服务器将停止到期实例以保护当前实例注册表信息。
在 Netflix 中,上述安全措施被称为自我保存模式,主要用于在一组客户端和 Eureka 服务器之间存在网络分区的情况下提供保护。
在这些场景中,服务器试图保护它已经拥有的信息。在发生大规模停机的情况下,可能会出现这样的情况,即客户端可能会获得不再存在的实例。
客户端必须确保它们对返回一个不存在或者没有响应的实例的 eureka 服务器具有弹性。
在这些场景中最好的保护是快速超时并尝试其他服务器。
在这种情况下,如果服务器无法从相邻节点获取注册表信息,它将等待几分钟(5分钟) ,以便客户端能够注册它们的信息。
服务器努力不向那里的客户端提供部分信息,因为它只向一组实例倾斜通信量,从而导致容量问题。
Eureka 服务器使用 Eureka 客户端和服务器之间使用的相同机制彼此通信,如本文所述。
另外值得注意的是,有几种配置可以在服务器上进行调优,包括在需要时在服务器之间进行通信。
在对等点之间的网络中断期间会发生什么?
在对等点之间的网络中断的情况下,可能会发生以下情况
- 对等点之间的心跳复制可能会失败,服务器检测到这种情况并进入自我保存模式来保护当前状态
- 注册可能发生在孤立的服务器中,一些客户端可能反映新的注册,而其他客户端可能没有
- 在网络连接恢复到稳定状态后,情况会自动纠正。当对等点能够很好地进行通信时,注册信息将自动传输到没有注册信息的服务器
底线是,在网络中断期间,服务器尽可能地保持弹性,但是在这段时间内,客户端可能对服务器有不同的看法。
Overriding Default Configurations
Eureka提供了内置的默认设置,适用于大多数场景。如果您想要覆盖缺省配置,您可能需要查看三种类型的配置。
您可以通过使用任何机制来扩展以下默认配置类,以提供您自己的配置值。
重要提示:请不要使用这些接口,它们只是用于文档的目的,将来可能会更改。
- 云或数据中心实例配置,两者都扩展了PropertiesInstanceConfig
- Eureka客户端配置
- Eureka服务端配置
注意,上面的内容还可以作为Eureka提供的所有上述配置的默认配置值的文档。
向注册信息添加自定义元数据
有时,您可能希望添加特定于部署环境的自定义元数据,以便进行注册和查询。
例如,您可能希望传播一个自定义环境id,该id应可用于您的特定部署env。Eureka提供了在标准注册数据之外添加自定义元数据作为键:值对的能力。
有两种方法可以做到这一点:
访问元数据
1 | String myValue = instanceInfo.getMetadata().get("myKey"); |
通过配置静态设置
eureka.metadata.mykey=myvalue的任何配置会将k:v键值对mykey:myvalue添加到eureka的元数据映射中。
通过代码动态设置
要动态地做到这一点,您首先需要提供您自己的EurekaInstanceConfig接口的自定义实现。
然后可以重载公共Map<String, String> getMetadataMap()方法,以返回包含所需元数据值的元数据映射。
请参阅PropertiesInstanceConfig以获得一个示例实现,它提供了基于上面系统的配置。
FAQ
对等点之间的网络中断时会发生什么?
在对等端点的网络中断的情况下,可能会发生以下情况。
- 对等端点之间的心跳复制可能失败,服务器检测到这种情况,进入自我保护模式,保护当前状态。
- 注册可能发生在孤立的服务器中,一些客户端可能会反映新的注册,而其他客户端可能不会。
这种情况在网络连接恢复到稳定状态后自动纠正。当对等体能够正常通信时,注册信息自动传输到没有注册信息的服务器。
底线是,在网络中断期间,服务器尽量保持弹性,但在此期间客户端可能对服务器有不同的视图。
为什么不使用HA代理进行负载均衡呢?
在AWS cloud中,由于其固有的原因,实例进出流量。
asg可以根据流量扩展或销毁实例。
无论我们是否使用HAProxy,挑战在于处理这种动态特性。
即使当你使用HAProxy时,也需要对它进行教育,了解进来和出去的实例,这正是Eureka所做的。
我可以考虑在中间层使用代理的原因之一是当您需要固定会话时。如果这是一个要求,HAProxy可以补充Eureka。
但是,由于在我们的场景中,大多数中间层服务都是非粘性的,所以我们没有理由通过代理来避免网络跳转。
这样做的另一个积极的副作用是,它使我们的客户端在Eureka服务端宕机时具有相当大的弹性,因为客户端拥有与需要与之通信的服务联系的所有信息。
通过HA代理有一个缺点,即您无法对代理中断进行弹性处理。
为什么不使用 Curator/Zookeeper 作为服务注册中心?
Zookeeper和Eureka在某些方面有一些相同之处,特别是在复制注册表信息方面。
Eureka可以使用zookeeper缓存注册表信息并复制相同的注册表信息,但复制只是Eureka提供的功能的一小部分。
除了复制之外,Eureka还处理各种其他事情:
- 处理注册、续订、到期和取消的REST端点。
- 保持实例信息的最新,以灵活的方式处理错综复杂的EIP绑定、部署回滚和自动伸缩。
- 对客户端和服务器之间以及对等体之间的网络中断具有弹性。
Zookeeper的力量在领袖选举、有序更新、分布式同步以及一致性保证(quorum)方面表现得尤为突出。
除了复制注册表外,以上所有方法都不适用于Eureka,我们必须处理以下复杂问题:
- 你现在必须找到一种方法,将EIPs分配给zookeeper,类似于Eureka。
- 当zookeeper出现故障时,处理故障。
而且,Eureka是精心构建的,没有任何外部组件的硬依赖。
- 大多数服务都依赖于Eureka来引导自己。
- 减少复杂性。
- 避免另一个失败点。